国产GPU编程的领域,迎来了重要的突破,摩尔线程在近日,宣布了开源 TileLang - MUSA 项目,这样的一个举措,有希望显著地降低国产AI 芯片的开发门槛,还能为本土算力生态,注入新的活力。
开源项目正式发布
2026一年的2月10一日,中国GPU设计方面的企业摩尔线程正式宣告要把其TileLang-MUSA编程语言项目进行开源。这个项目达成了对TileLang语言的完整支持,目的在于充分地释放国产全功能GPU的硬件性能。这一回的开源被看作是该公司构建本土算力生态的关键步骤。

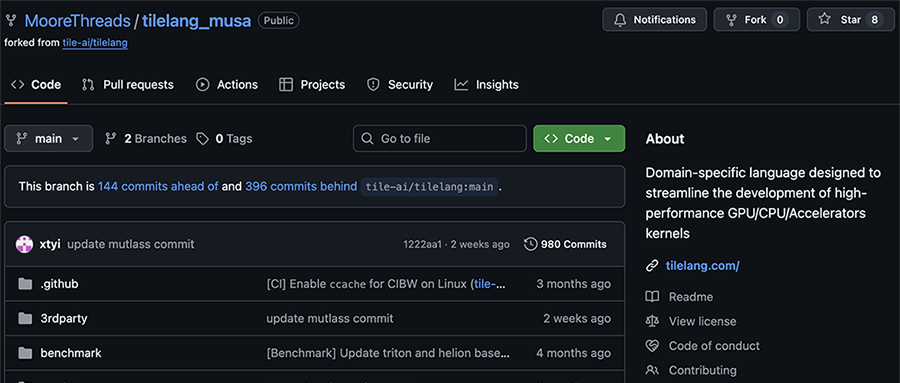
近日,该项目在代码托管平台GitHub上公开了。摩尔线程官方称,开源是为吸引更多的开发者参与进来,一起推动国产GPU软件栈走向成熟。在此之前,该其司针对多代自研GPU产品,完成了该项目的功能验证以及特性开发。
技术定位与核心价值
TileLang是一种编程语言,它基于张量分块抽象,是高性能AI算子编程语言,属于领域特定语言,它采用声明式语法与类Python前端,它允许开发者以接近数学公式的形式描述计算意图,编译器会在之后自动完成循环优化、内存调度等复杂任务。
该语言的核心理念是借助高级抽象来降低编程复杂度,并且不使底层硬件性能受到牺牲。它具备“一次编写,多架构运行”的跨平台能力,能为AI算子开发提供一条新的、高效的路径。在需要快速迭代的AI模型开发场景里,这一特性显得尤为重要了。
硬件兼容与架构映射
TileLang - MUSA项目,已同摩尔线程多代全功能GPU达成适配验证,其中涵盖面向智算场景的MTT S5000以及MTT S4000计算卡。该项目达成了TileLang高层语义至摩尔线程底层MUSA计算架构的精准映射,进而确保了编程模型与硬件特性的紧密结合。
在具体的技术实现层面,编译器具备自动调用MUSA架构所拥有的MMA矩阵乘累加指令的能力,借此充分施展张量核心的计算潜在能力。与此同时,它还能够自动开展多级内存之间的数据搬运工作,借助异步拷贝指令有效地将访存延迟予以掩盖,并且完整地支持Warp级并行优化这一特性。
实测效能大幅提升
在实际开展的测试期间,TileLang-MUSA呈现出了能够兼顾开发效率以及运行性能的那种优势,针对大语言模型里的关键算子FlashAttention-3以及通用矩阵乘而言,于MTT S5000计算卡之上所进行的测试得出結果引人关注。
运用TileLang-MUSA来展开开发,所需要的代码数量跟手写MUSA C++代码相比较,减少了大概90%,代码的逻辑变得更加清晰。在性能这一方面,所生成的算子性能在典型配置的情形下,矩阵乘法最高能够达到手写优化版本的95%,FlashAttention-3同样也能够达到85%。这证实了它的高效性。
降低迁移与开发门槛
这个项目被推出,致使存在着的TileLang用户,能够运用几乎是零成本的办法,把已经有的算子逻辑转移到摩尔线程GPU平台。对于那些不熟悉底层MUSA指令集的数量众多的AI算法工程师来讲,这给出了一个高层次的友善开发入口。
借由对FlashAttention等前沿模型关键算子高效开发予以支持,此项目有希望加快大语言模型等AI应用于国产算力平台上的部署以及落地进程。这给摆脱对特定国外硬件平台的依赖供给了切实的工具支撑。
生态建设未来规划
摩尔线程宣称,TileLang - MUSA的开源仅是起始步骤,公司打算持续推动平台以及生态构建,用心于塑造一个涵盖从单一算子直至完整大模型的国产算力统一加速平台,未来的工作会包含深度整合主流AI框架。
该公司另外有着将复杂模型架构予以跨算子调度以及实现全球优化的规划安排 ,并且会更进一步地去把调试以及性能分析工具链加以完备。其长久的目标是借由持续性的性能优化 ,使得所生成代码的性能能够稳定地抵达手写优化版本的百分之九十之上 ,从而搭建起一个更为开放 、更便于使用的开发生态。
难道您觉得,这类能够降低国产芯片开发门槛之所为的开源工具,真的就可以切实推动国内围绕AI算力那种特有的生态走向的独立以及繁荣吗?欢迎在评论区域分享您自身的观点,要是您认为本文是具备价值的,那就请点赞予以尽力支持以及分享给更多特别看重科技创新的朋友。