在人工智能模型都在竞相追逐参数量级的浪潮当中,有一种“瘦身”革命正暗暗地兴起,目的是要让强大的语言模型可以进驻每个 人的口袋。腾讯公司在2026年2月10日正式发布了一款面向消费级硬件的超小型模型HY-1.8B-2Bit,它那极致的压缩技术引起了行业对于端侧智能未来的新想象。
模型发布的核心信息
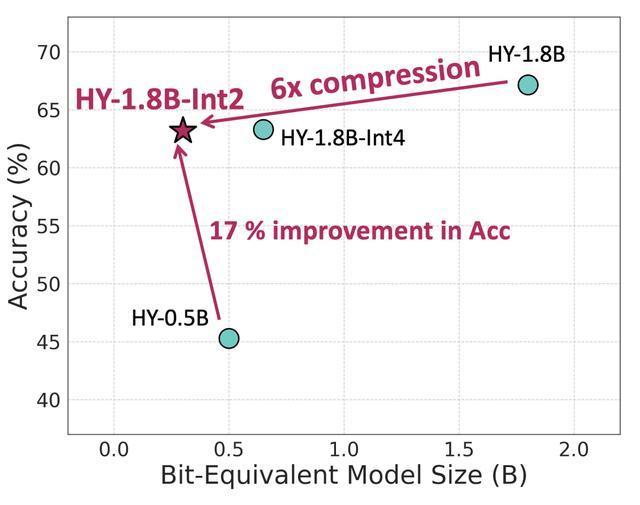
今日,腾讯混元团队宣称推出HY - 1.8B - 2Bit模型,这是首个借助产业级2比特端侧量化方案达成的、消费级硬件能够使用的模型。此模型等效参数量只有0.3B,模型文件大小被压缩到大约300MB,运行的时候内存占用只需600MB。
这一回的发布,标志着超低比特量化技术朝着从实验室迈向产业应用的关键一步迈进。腾讯那一方着重表明,该模型意在解决手机、耳机以及智能家居等设备针对模型离线部署与数据隐私的迫切需求,给边缘计算场景提供了全新的可行方案。
技术路径与量化突破
该模型是经由针对此前所发布的Hunyuan-1.8B-Instruct模型,实行2比特量化感知训练而产出的。同常见的训练之后的量化方法有所不同,量化感知训练于模型训练进程当中就模拟了量化效果,故而显著地减少了精度损失。

针对原始大小仅仅只有1.8B的模型来讲,把它压缩到2比特是具有极大挑战性的一项任务。混元团队借助数据优化,运用弹性拉伸量化,采用创新的训练策略,最大程度地提高了量化之后模型在数学、代码、科学等方面的综合能力。
性能表现与基准测试

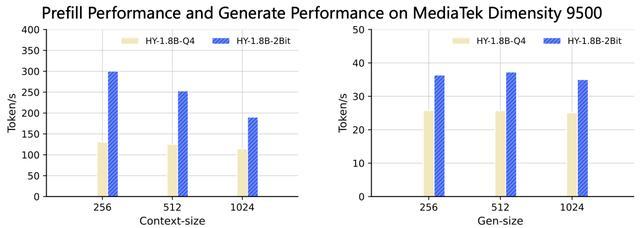
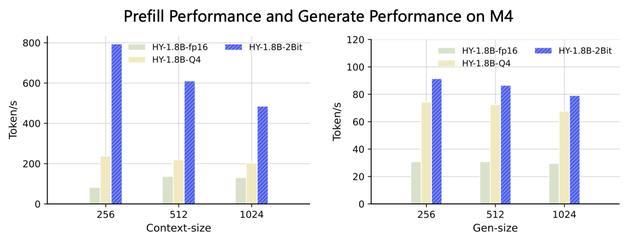
依据官方所披露的测试数据,HY - 1.8B - 2Bit模型于多项指标方面,和运用4比特训练后进行量化的模型版本表现差不多。在MacBook M4芯片的测试环境当中,该模型于1024 tokens的输入长度之内,首字生成时延相较于原始精度模型有3至8倍的加速。
在生成速度这块儿,于常用上下文窗口设置情形下,HY - 1.8B - 2Bit能够达成起码2倍的稳定加速效果。在联发科天玑9500移动平台那儿所做的测试也表明,它的首字时延相比4比特量化版本有1.5至2倍的加速幅度。
部署适配与运行效率
腾讯混元为方便开发者集成,提供了该模型的gguf-int2格式权重文件,还提供了bf16伪量化权重。该模型已完成在Arm等主流计算平台上的适配,能够部署于支持Arm SME2技术的移动设备。
模型运行之际,内存占用唯有600MB,此一数据比对诸多常规手机应用程序的占用空间要低,这致使在资源受限的端侧设备之上进行高效且稳定的推理化作可能,这而为完全离线的智能语音助手、实时翻译、个性化推荐等应用扫除了技术障碍。
“全思考”能力与灵活应用
需要留意的是,HY - 1.8B - 2Bit模型延续了原本指令模型具备的全部思考能力,用户能够依据实际所需,灵活地挑选简洁的思维链模式去处理简单的查询,或者调用详尽的长思维链模式来应对复杂的任务。
这种设计使得应用开发者能够依据其产品所面临的那复杂性以及设备资源的限制情况,去动态地调整模型的“思考深度”,比如说,当在耳机之上进行即时语音命令识别之际能采用简洁模式呢,然而在平板电脑上处理复杂文档摘要之时就可以启用详细推理模式哟。
未来展望与技术挑战
腾讯混元团队表明,当下,HY - 1.8B - 2Bit模型的能力,依旧在监督微调的训练流程,以及基础模型其自身的性能上限方面受到限制。模型于极端压缩状况下,和全精度版本的能力之间存在的差距,是切实存在的。
未来,团队的研究重点会朝着强化学习和模型蒸馏等技术路径有所转变,目的是能够进一步缩小低比特量化模型与全精度模型之间的性能差距。这对于在更为广泛的边缘设备上达成真正实用、可靠的大语言模型部署而言有关联性。
随着 HY - 1.8B - 2Bit 模型发布,一个关键问题出现于整个行业面前,即当此模型小到足以嵌入任何智能设备时,你最期待在哪些日常场景里去体验完全离线、隐私无忧的本地 AI 助手?欢迎于评论区分享你的设想,接着点赞、分享本文,以使更多人参与到关于未来智能边缘计算的讨论之中。